WheatGOAT: Generalizable Object-Aware Tracker via Discriminative Region Semantic Learning for Wheat Ear Counting. Accurately counting wheat ears is vital for yield prediction and crop management but is challenging due to occlusion, variety differences, lighting, and complex backgrounds. We propose WheatGOAT, a robust object-aware tracker with three key modules: a selector that isolates wheat regions from clutter, a learner that enhances distinction of dense and overlapping ears through region-level semantics, and a hierarchical refiner that uses multi-scale context for precise recognition across varied ear shapes and layouts.
overview: As shown in Figure 1, WheatGOAT includes a backbone network, an Object-Background Selector (OBS), an Object Perception Learner (OPL), a Hierarchical Refiner (HR), and a Prediction Module (PM). The backbone extracts features from wheat images, OBS separates wheat ears from the background, OPL uses vision-language learning to better distinguish ears, HR refines details using multi-scale context, and PM generates a precise density map for counting. This combined approach improves accuracy and adapts well to different field conditions and crop types.
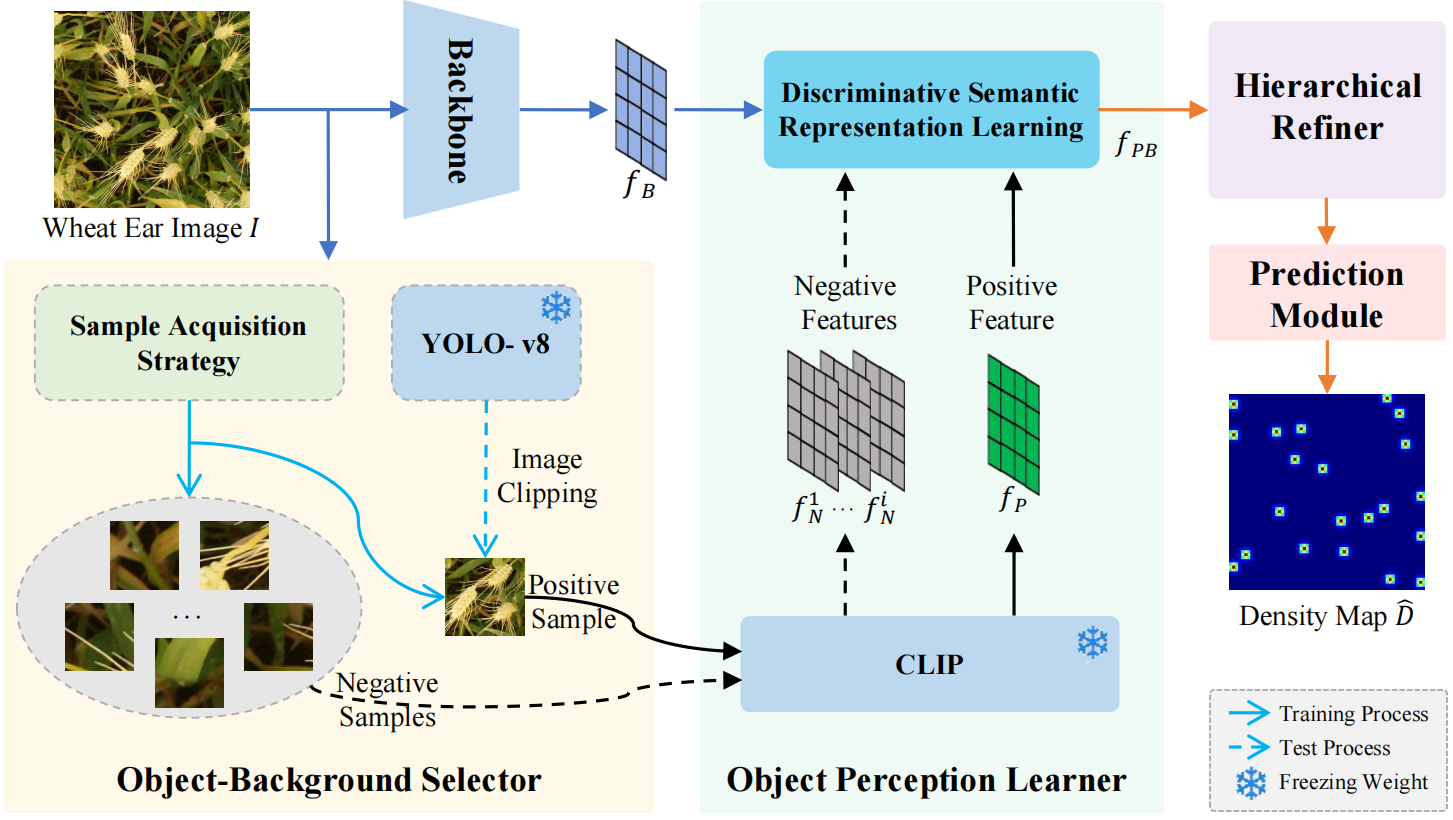
Figure 1: The overall architecture of WheatGOAT.
BackboneThe backbone is the core feature extractor that greatly impacts the model’s accuracy, robustness, and efficiency. To balance performance and speed, we use the first ten layers of a pre-trained VGG16 network, which effectively captures detailed spatial features while keeping the model lightweight. Initialized on ImageNet, this backbone leverages broad visual knowledge to speed up training and improve generalization, enabling the model to reliably detect wheat ears despite environmental changes with reduced computational cost.
Object-Background Selector (OBS) In natural wheat fields, dense growth, occlusion, and shape variation make detection difficult, as traditional models struggle with background noise and poor localization. To overcome this, we introduce the Object-Background Selector (OBS), which explicitly separates wheat ears from clutter by creating structured positive (wheat) and negative (background) sample pairs. During training, positive patches are cropped around labeled wheat ears, while negative patches are taken from nearby non-ear areas with similar context. This contrastive sampling sharpens the model’s focus on meaningful features and improves robustness. At inference, coarse ear boxes derived from annotations guide a YOLOv8 detector to provide precise localization, enhancing overall counting accuracy and tracking performance.
OPL: As shown in Figure 1, the Object Perception Learner (OPL) tackles challenges like overlapping wheat ears, lighting changes, and background clutter by enhancing region-level discrimination. Using CLIP’s ViT-B/32 vision transformer, OPL extracts rich semantic embeddings from positive (wheat) and negative (background) samples, while the backbone provides global visual features. Through dot-product attention between these embeddings and the global features (illustrated in Figure 2), OPL guides the model to focus on meaningful wheat ear regions, improving robustness and accuracy in complex field conditions.
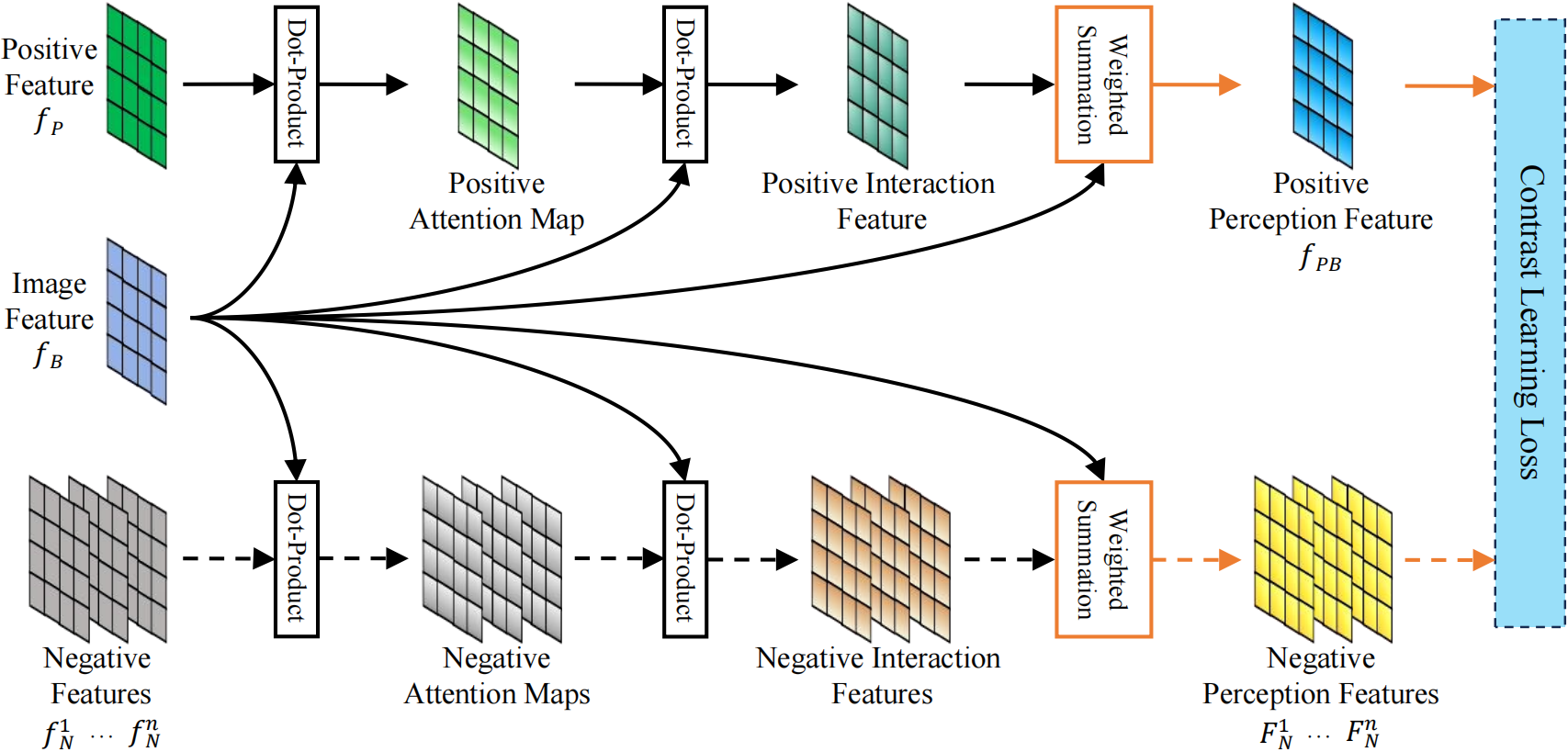
Figure 2: Illustration of discriminative semantic representation learning in the Object Perception Learner (OPL).
HR: As shown in Figure 3, the Hierarchical Refiner (HR) improves detection of wheat ears by handling their diverse sizes, shapes, and densities in real fields. It tackles missed small ears and occlusion issues by enhancing multi-scale feature learning and applying joint attention optimization, strengthening the model’s ability to recognize complex and overlapping patterns.
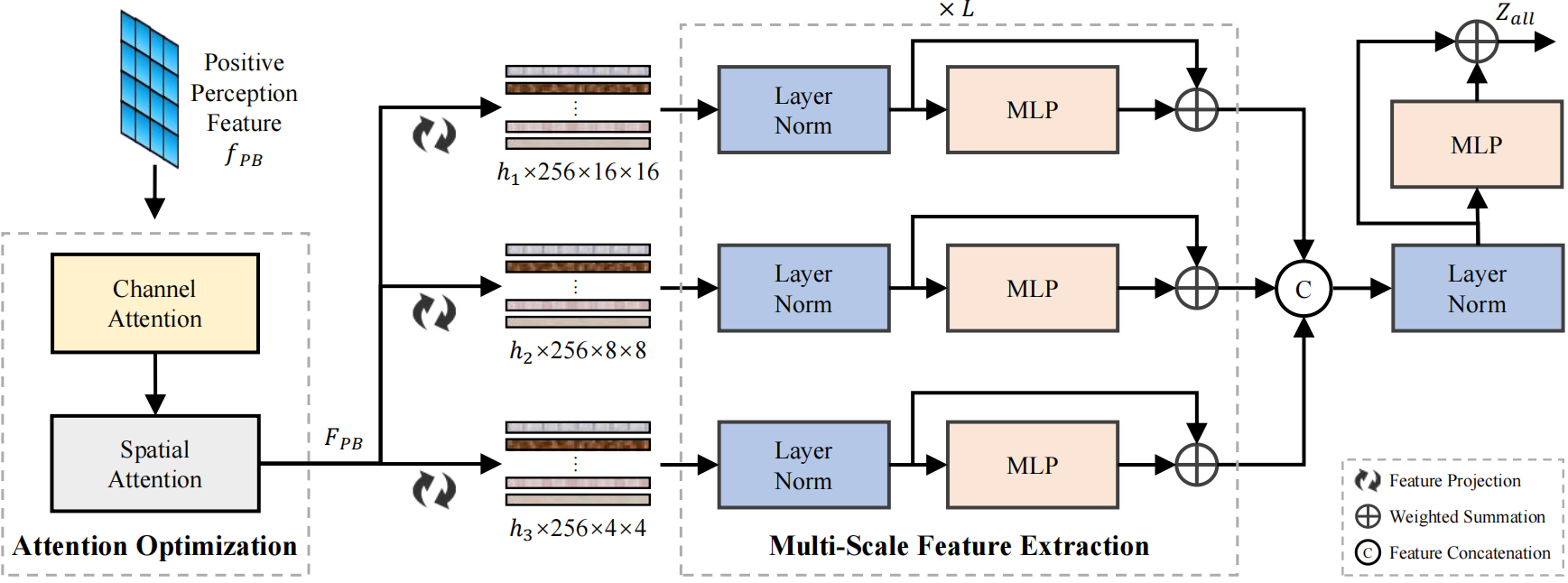
Figure 3: The details of the Hierarchical Refiner (HR).